 Les codes de la Bible exactement
Les codes de la Bible exactement
Quand je n'étais qu'une masse informe, tes yeux me voyaient ; Et sur ton livre étaient tous inscrits
les jours qui étaient fixés, avant qu'aucun d'eux n'existe.
Psaume 139:16
En 1989, Witztum publia un livre en Hébreu intitulé Hamimad hanosaf (la dimension additionnelle) dans lequel il présente environ deux cents tables, contenant principalement des éléments relatifs à l'histoire d'Israel depuis son origine jusqu'à nos jours. Il y décrit brièvement son concept de l'écriture à deux dimensions.
Il expose également dans ce livre un protocole préliminaire d'évaluation statistique de ces tables, et arrive à des probabilités inférieures a 1 /1.000.000 pour la plupart d'entre elles.
L'ouvrage fut préfacé en ces termes par un groupe de mathématiciens de la plus haute notoriété:
"Ces travaux représentent une recherche sérieuse menée par des chercheurs sérieux. Puisque l'interprétation du phénomène en question est énigmatique et controversée, on est en droit d'exiger un niveau de preuve statistique au delà de ce que l'on exigerait pour des conclusions plus routinières...
Les résultats obtenus sont suffisamment frappant pour mériter une plus large audience et encourager des études plus poussées."
Professeur H. Furstenberg, Université Hébraïque de Jerusalem,
Professeur I. Piateski-Shapiro, Université de Tel-Aviv et Université de Yale,
Professeur D. Kazhdan, Université d'Harvard,
Professeur J. Bernstein, Université d'Harvard.
Préalablement à leur publication, Rips et Witztum démontrèrent que lorsque des paires de mots conceptuellement corrélés apparaissent par sauts de lettres équidistants dans la Torah, dans leur intervalle minimal, ils se trouvent trop souvent à un degré de proximité très étroit (tendant vers zéro), pour que cela soit du au hasard.
Ces paires de mots peuvent être reliés à des concepts d'ordre général, par exemple "marteau" et "enclume", "homme" et "femme", etc..., ou géographique, physique, chimique, médical, etc...
Pour illustrer le phénomène, observons le diagramme ci-dessous relatif à l'expérimentation de Rips et Witztum portant sur 10.000 paires de mots-clé:
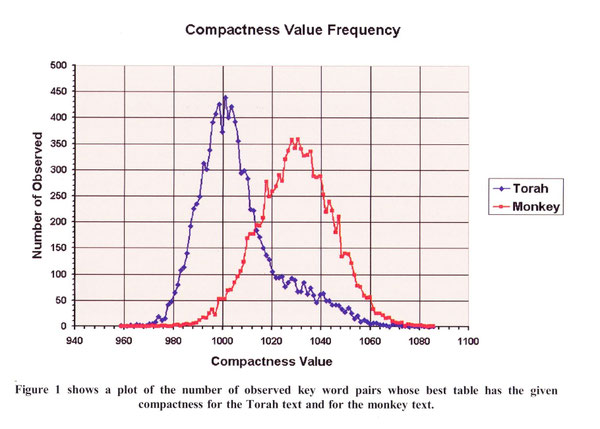
L'expérimentation compare la distribution du degré de proximité de 10.000 paires de mots-clé observées dans la Torah par rapport à celui des textes de contrôle (monkey)
Le degré de proximité des mots est déterminé par la compacité des tables dans lesquelles ils apparaissent, c'est à dire leur surface, déterminée par le nombre de lettres de la table.
En ordonnées, le nombre de paires observées.
En abscisses, la valeur de compacité des tables.
Nous constatons que la disposition des mots-clé conceptuellement corrélés apparaissant dans la Torah par sauts de lettres équidistantes n'est pas de nature aléatoire.
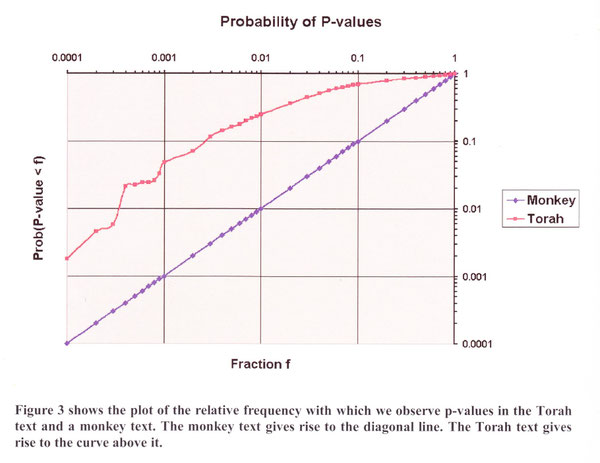
Ce diagramme montre la fréquence des valeurs p des tables observées dans les textes de contrôle (ligne diagonale) et dans la Torah (courbe en rouge)
L'expérimentation des Grands Sages
En 1985, Rips et Witztum décidèrent de réaliser une expérimentation formelle qui serait soumise à une publication scientifique, qui consisterait à mesurer le degré de proximité de deux mots conceptuellement corrélés, apparaissant dans la Genèse dans leur ELS minimale. Il choisirent pour cela des paires de mots formées des noms de personnalités rabbiniques célèbres avec leur date de naissance ou de mort apparaissant par Sauts de Lettres Equidistantes (ELS) dans le livre de la Genèse.
Cela prendra 6 ans, entre la soumission de leurs travaux au journal Statistical Science et sa publication effective en 1994.
Pour réaliser leur expérimentation, Rips et Witztum s'associèrent a Yoav Rosenberg, PhD en sciences informatiques de l'Université Hébraïque, spécialiste de techniques mathématiques avancées permettant de détecter avec une grande précision des signaux flous dans une mer statique, et utilisées pour des applications spécifiquement militaires. Ce fut Yoav Rosenberg qui écrivit le programme de l'expérimentation. L'article sera désormais reconnu par l'acronyme WRR (Witztum, Rips, Rosenberg)
Elle fut réalisée en deux étapes.
Première expérimentation des Grands Sages:
- La base de donnée fut composée d'un ensemble de 34 personnages avec leur date de mort ou de naissance, ayant vécu entre le 9ème et le 18ème siècle de l'ère commune. Chaque nom et sa date constituant ainsi une paire dont on devrait évaluer la proximité selon des critères précis déterminés a l'avance: Les noms des Grands Sages seraient sélectionnés selon des critères arbitraires qui limiteraient la base de données, a partir des références biographiques de l'Encyclopédie des Grands Hommes d'Israel. Seuls les plus connus (contenant au moins trois colonnes de textes furent sélectionnés)
- Ensuite seuls les noms pour lesquels une date de naissance ou de mort est donnée seraient utilisés.
- De cet ensemble, pour des raisons de limitation technique, seuls les noms d'une certaine fourchette de longueur donnée seraient utilisés (cette sélection n'affecte aucunement l'issue des résultats et facilite des contre-épreuves ultérieures)
- Chaque date fut écrite en trois formats d'Hébreu standardisés (par exemple: "9 Tishri", "9 de Tishri", ou "le 9 de Tishri")
Ensuite:
- On mesura le degré de compacité de chaque paire de mots codés dans leur intervalle minimum.
- On mesura le degré global de compacité de l'ensemble de la base de données pour obtenir une valeur moyenne de l'expérimentation (au plus on obtient de paires compactes, et au plus chaque paire est compacte, au plus la probabilité que le phénomène soit réel augmente)
- La compacité moyenne de l'expérimentation fut comparée avec une moyenne théorique, obtenue avec un grand nombre de contrôles, en utilisant une variante de la simulation de Monte Carlo (protocole mathématique utilisé en sciences statistiques et probabilistes, permettant d'estimer avec la meilleure fiabilité possible l'issue d'évènements aléatoires, comme par exemples dans les jeux de hasard, la finance, la physique des particules, etc...) En bref, ce protocole permet d'éviter que n'importe quel fou avec un ordinateur puisse trouver ce qu'il veut dans un texte quelconque.
La liste des noms fut préparée avant que l'expérimentation ne commence, par le Professeur Shlomo Havlin, alors Directeur du Département de Bibliographie et Documentation de l'Université Bar Ilan. Les règles d'orthographe ainsi que la forme des dates hébraïques furent aussi établies a priori par le linguiste Yaakov Orbach.
Quelques uns des Grands Sages encodés dans la Genèse:
Nom
Rabbi Shlomo Yitzhaki
Rabbi Abraham Ibn-Ezra
Rabbi Moshe Ben Maimon
Rabbi Avraham
Rabbi Yosef Caro
Rabbi David Ganz
Rabbi Moshe Chaim Luzzatto
Rabbi Yisrael ben Eleazar
Rabbi Eliyahu ben Shlomo
Année
1105
1164
1204
1287
1575
1613
1746
1760
1797
Commentaires
Rashi, éminent commentateur biblique et talmudique
Le Raviyeh, illustre poète et liturgiste
Le Rambam, médecin, philosophe, le personnage le plus illustre du Judaïsme post-biblique
Fils du Rambam, dirigeant de la communauté juive d'Egypte
Mahariyeh Caro, codificateur de la loi juive orthodoxe
Tzemach David, astronome, mathématicien, historien
Ramchal, enfant prodige, kabbaliste remarquable, unificateur de la pensée juive
Le Baal Shem Tov, fondateur du Hassidisme
Le Gaon de Vilna, enfant prodige, mathématicien, illustre exégète biblique et talmudique
Les mesures des convergences montra qu'il existe une très forte tendance pour l'ensemble des noms de personnalités à converger avec leur date associée.
Les résultats obtenus stupéfièrent les chercheurs eux-mêmes, les probabilités qu'ils se produisent par simple chance étaient astronomiquement petites (moins d'une chance sur 50.000)
L'implication de ces résultats défiait la raison; il ne s'agissait plus ici de paires de mots communs conceptuellement corrélés, mais des noms et de la vie d'individus codés dans un texte écrit entre 2000 et 3000 ans avant leur naissance!
La table ci-dessous montre un exemple de convergence remarquable: Le Gaon de Vilna avec sa date de naissance.
La probabilité pour qu'une table aussi compacte apparaisse par hasard est de 34,5/100.000


Deuxième expérimentation des Grands Sages:
WRR publièrent leurs résultats dans un rapport a l'Université Hébraïque à l'automne 1986.
Le rapport fut envoyé au Professeur Diaconis, un statisticien. Celui-ci, pensant que les résultats expérimentaux étaient dus a un ajustement du protocole à la base de données, proposa qu'une nouvelle liste de personnalités célèbres soient préparée pour être expérimentée en utilisant exactement le même programme.
Pour établir la nouvelle liste, WRR prirent les personnalités dont les entrées dans l'Encyclopédie étaient comprises entre 1,5 et 3 colonnes, et pour lesquels une date de naissance ou de mort était indiquée.
Les dates furent écrites dans exactement le même format établi précédemment.
Cette fois aussi, la liste des noms fut préparée a priori par le Professeur Havlin, en utilisant les mêmes critères professionnels.
Les mesures devaient être calculées en utilisant le même programme que pour la première expérimentation.
Un article décrivant les deux expérimentations fut publié dans un rapport a l'Université Hébraïque a l'hiver 1988.
Une courte version de cet article fut soumise pour être publiée dans les Comptes-rendus de l'Académie Nationale des Sciences par le Professeur Robert Aumann; le Professeur Diaconis en fut l'un des critiques. Dans une lettre au Professeur Aumann, datée du 3 Aout 1988, le Professeur Diaconis suggère qu'un test de permutation soit utilisé pour estimer la valeur p du résultat.
Finalement, les détails du test, le nombre de permutations, et le niveau de pertinence requis furent convenus d'un commun accord par le Professeur Diaconis et le Professeur Aumann dans une lettre datée du 7 Septembre 1990.
Le Professeur Aumann envoya une copie de l'accord a WRR. Sur sa recommandation, un nouvel article fut rédigé avant le lancement de l'expérimentation; Cette version décrivait le nouveau test, sans les résultats puisqu'ils n'existaient pas encore. Cet article fut envoyé au Professeur Diaconis et à plusieurs autres statisticiens bien connus; ils approuvèrent le test tel que décrit dans l'article, et ils stipulèrent, chacun indépendamment, le niveau de pertinence qui devait être appliqué.
L'expérimentation fut lancé a l'hiver 1991; les résultats furent hautement significatifs:
valeur p = 0,000016
Soit 1 chance sur 62.500 qu'ils soient dus au hasard, bien au delà des limites fixées par le comité d'experts qui les avait fixées à 1 sur 1000.
L'article fut finalement publié dans le journal Statistical Science, Vol. 9 (1994) No. 3, 429-438, après trois années supplémentaires d'analyses additionnelles et de vérifications par le comité d'édition.
Robert Kass, alors éditeur de Statistical Science, actuellement doyen du Département des Statistiques à l'Université Carnegie-Mellon de Pittsburgh, commenta ainsi l'issue des contrôles:
"Nos referees ont été soufflés: leur convictions préalables les laissaient penser qu'il n'était pas possible que le livre de la Genèse puisse contenir des références significatives à des personnalités contemporaines, et pourtant, après avoir effectuer des vérifications et analyses additionnelles, les effets persistaient. L'article est donc offert aux lecteurs de Statistical Science comme une énigme à résoudre."
Comme Robert Kass le mentionna, l'article avait subit un nombre inhabituel d'examens critiques.
Une procédure identique pour toutes les paires fut effectuée avec:
-
Une portion de la traduction en Hébreu du roman "Guerre et Paix", de la même longueur que la Genèse.
-
Le livre d'Esaïe.
-
Le livre de la Genèse randomisé en permutant toutes les lettres du texte.
-
Le livre de la Genèse randomisé en permutant tous les mots dans les versets.
-
Le livre de la Genèse randomisé en permutant tous les versets et en laissant les séquences de mots intactes dans les versets.
-
D'autres textes hébreux anciens.
Aucun de ces textes ne mirent en évidence une quelconque relation entre les noms et les dates formés par des ELS, on ne pouvait en distinguer les résultats de ce qui se produit simplement par hasard. Seul le livre de la Genèse montra une déviation colossale des résultats attendus par hasard.
Cette valeur de 1/62.500 fut obtenue en testant les paires nom/date authentiques contre 999.999 pseudo-paires (nom associé à une date incorrecte), comme suggéré par le Professeur Persi Diaconis.
Soulignons encore le fait qu'une valeur p de cet ordre (0,000016 ou 1/62500) est rarement atteinte en sciences statistiques. De plus, la méthode de mesure de ces probabilités fut développée par les referees eux-mêmes. La grande majorité des revues scientifiques acceptent fréquemment à la publication des articles dont les hypothèses sont validées a un niveau de pertinence de 0,05 (soit 1 chance sur 20 que les résultats soient l'effet du hasard). Pour des décisions médicales impliquant des questions de vie ou de mort, on peut demander des probabilités de 1/50. Parce que le phénomène des ELS semblait si étrange, et ses implications si vastes, l'éditeur et le comité de lecture montèrent la barre a 1/1000 (suivant la suggestion des Professeurs émérites cités précédemment). Les résultats furent 60 fois meilleurs que le niveau requis...
L'histoire de cette expérimentation des Grands Sages n'en est pas restée la, puisque qu'elle a été ensuite répliquée avec succès par d'autres mathématiciens des plus sceptiques:
Alexander Pruss, Ph.D., mathématicien et statisticien de l'Université de Colombie Britannique, puis de celle de Pittsburg, réalisa ses propres réplications non officielles de l'étude de WRR et en fit un rapport sur la liste internet de discussion savante "B-Hebrew", modérée à l'Université de Virginie.L'approche et l'analyse du Professeur Pruss sont particulièrement instructives, car il traite les codes du point de vue d'un critique qui a conclu que les codes ne sont pas réels. Il répéta indépendamment l'expérimentation reporté dans Statistical Science (deuxième liste des Grands Sages), en écrivant son propre logiciel sur un système informatique différent. Il dit ne pas trouver d'erreur dans son rapport, et il considère la conception expérimentale "une très belle étude auto-contrôlée qui, à proprement parler, ne nécessite même pas de textes de contrôle pour que les statistiques soient valides."
Vint ensuite la réplication d'Harold Gans, mathématicien expert en cryptologie attaché a la NSA, qui non seulement confirma les résultats de WRR, mais il poussa l'expérimentation encore plus loin.
Nous verrons son histoire en détail après avoir considérer les arguments des détracteurs.
